ASCII — standard kodowania znaków: definicja, historia i zastosowania
ASCII — kompletny przewodnik: definicja, historia, kodowanie 128 znaków, znaki kontrolne oraz praktyczne zastosowania w informatyce i transmisji danych.
ASCII (wymawiane az-kee, czasem ass-key w amerykańskim angielskim) to standardowa tabela znaków stosowana w informatyce. Nazwa pochodzi od angielskiego American Standard Code for Information Interchange. ASCII jest prostym kodem binarnym używanym przez komputery oraz urządzenia komunikacyjne do reprezentowania liter alfabetu angielskiego, cyfr i popularnych symboli. Został opracowany w latach 60. XX wieku i bazuje na wcześniejszych rozwiązaniach stosowanych w systemach telegraficznych.
Galeria obrazów
1 Obraz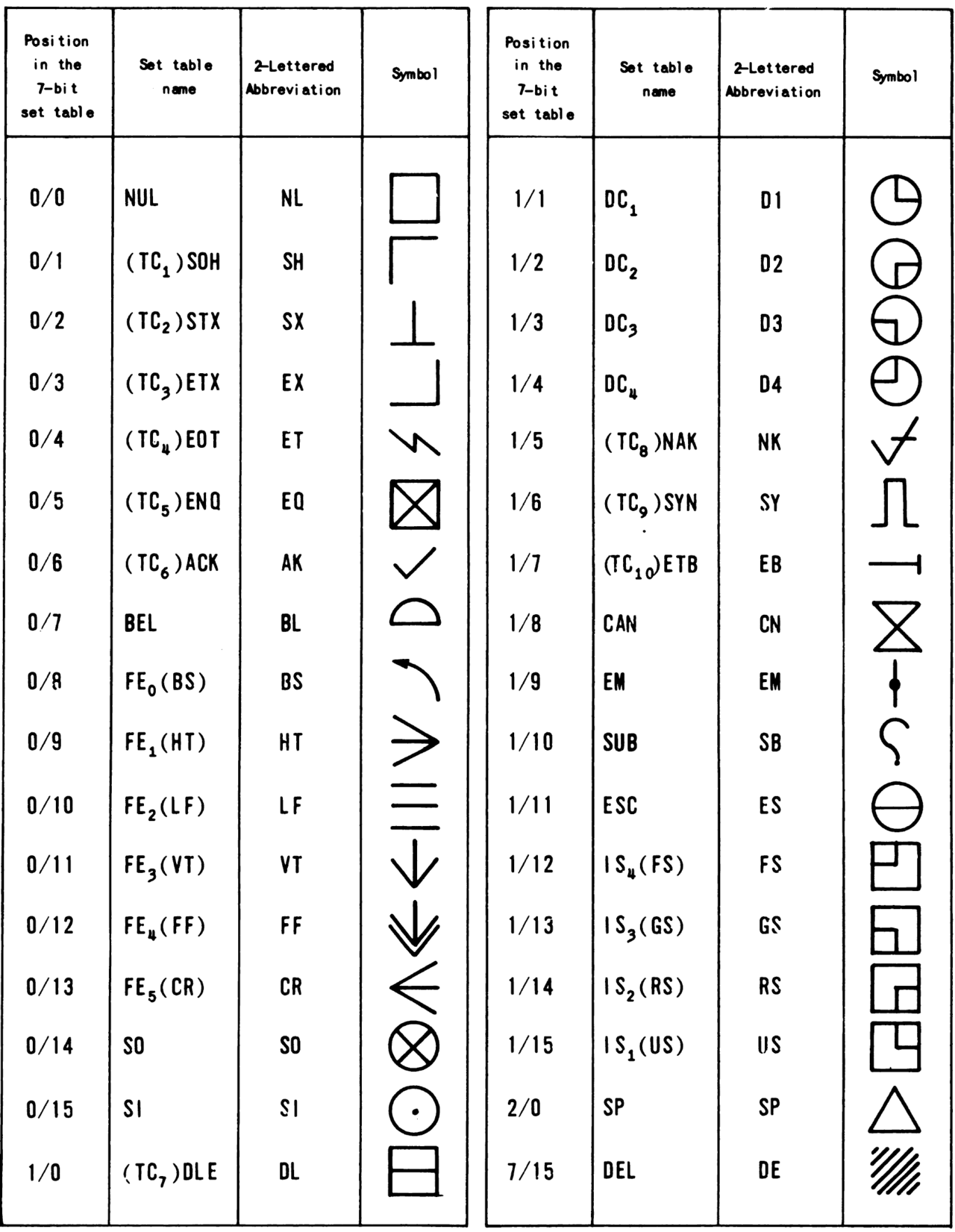
Jak działa ASCII
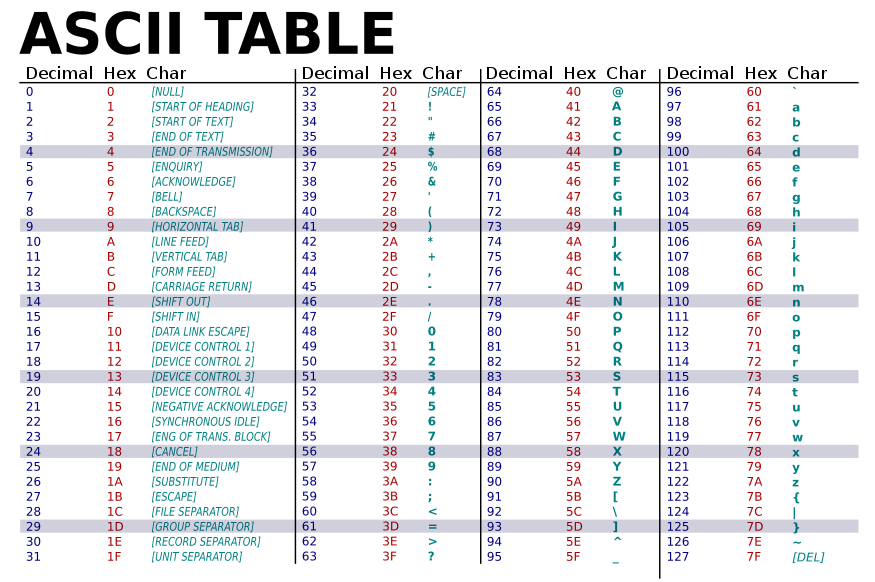
Klasyczny ASCII definiuje 128 znaków o numerach od 0 do 127. Obejmuje to zarówno znaki drukowalne (litery, cyfry, znaki przestankowe), jak i znaki kontrolne (niedrukowalne), które służą do sterowania transmisją i formatowaniem tekstu. Przykłady znaków drukowalnych to małe i wielkie litery a–z, A–Z, cyfry 0–9 oraz symbole typu ?&!. Znaki kontrolne znajdują się „w lewej kolumnie” typowych tabel ASCII i nie są wyświetlane jako znaki graficzne.
Technicznie ASCII jest 7-bitowym kodem: każdy znak ma przypisany kod od 0 do 127. Przykładowo, duża litera A ma kod binarny 1000001 (czyli 65 w systemie dziesiętnym i 41 w systemie szesnastkowym). W praktyce, gdy dane były przesyłane lub przechowywane w systemach opartych na 8-bitowych bajtach, dozwolone było dopisywanie dodatkowego bitu (np. bitu parzystości) jako ósmego bitu — stąd pojawiają się opisy wykorzystujące 8 bitów na bajt. Bit parzystości (parzystości) bywał używany do wykrywania prostych błędów przesyłu, co było istotne przy hałaśliwych łączach modemowych i szeregowym przesyle danych.
Znaki kontrolne — przykłady i zastosowanie
Znaki kontrolne ASCII nie są drukowane, ale pełnią konkretne funkcje. Najbardziej znane to:
- NUL (0x00) — znak o kodzie 0, często używany jako terminator łańcuchów w języku C;
- BEL (0x07) — sygnał dźwiękowy (bell);
- BS (0x08) — backspace (kasowanie poprzedniego znaku);
- HT (0x09) — tabulator poziomy (tab);
- LF (0x0A) — line feed, przesunięcie do nowej linii (Unix, Linux);
- CR (0x0D) — carriage return, powrót karetki (classic Mac OS używał CR, Windows używa CR+LF);
- ESC (0x1B) — escape, sygnalizuje sekwencje sterujące; oraz
- DEL (0x7F) — kod 127, historycznie używany do oznaczania usunięcia znaku.
Wiele z tych znaków kontrolnych nie jest dziś używanych w swoich pierwotnych rolach, ale niektóre — jak LF i CR — nadal decydują o sposobie łamania linii i normach wymiany plików tekstowych.
Historia i standardyzacja
ASCII powstał jako wspólny standard umożliwiający interoperacyjność różnych maszyn i urządzeń komunikacyjnych. Jego projekt opierał się na uprzednich kodach telekomunikacyjnych (np. kodach telegraficznych). W kolejnych dekadach ASCII był wielokrotnie przyjmowany i adaptowany przez producentów sprzętu oraz autorów protokołów sieciowych i systemów operacyjnych.
Rozszerzenia, kompatybilność i relacja z Unicode
Ze względu na ograniczenie do 128 znaków ASCII nie pozwalał na reprezentację liter z akcentami ani znaków alfabetów innych niż angielski. W praktyce pojawiły się różne „rozszerzone” 8-bitowe zestawy znaków (np. ISO-8859-1, często mylony z Windows-1252), które wykorzystują dodatkowe 128 pozycji (128–255) do znaków lokalnych i symboli graficznych. Jednak te rozszerzenia nie były wzajemnie w pełni zgodne.
Prawdziwym rozwiązaniem problemu wielojęzyczności stał się Unicode — uniwersalny system kodowania znaków obejmujący miliony znaków z różnych pism. Najpopularniejszym sposobem kodowania Unicode w plikach tekstowych jest UTF-8, który zachowuje pełną kompatybilność z ASCII: bajty o wartościach 0–127 w UTF-8 odpowiadają dokładnie znaków ASCII. Dzięki temu pliki „w ASCII” są jednocześnie poprawnymi strumieniami UTF-8.
Zastosowania i ograniczenia
ASCII jest nadal fundamentem wielu technologii i protokołów:
- pliki zwykłego tekstu (plain text), skrypty, pliki konfiguracyjne;
- proste protokoły sieciowe i nagłówki (np. protokoły SMTP, HTTP historycznie bazowały na tekstowych formatach ASCII);
- programowanie — wiele języków i narzędzi zakłada zgodność z ASCII dla podstawowych znaków i operatorów;
- komunikacja przez porty szeregowe i terminale, gdzie używano bitu parzystości i 7/8-bitowych formatów transmisji.
Główne ograniczenie ASCII to brak wsparcia dla znaków spoza podstawowego zestawu angielskiego (brak liter diakrytycznych, znaków cyrylicy, ideogramów itp.). Współczesne aplikacje i strony internetowe korzystają z Unicode/UTF-8, ale ASCII pozostaje istotną częścią historii i infrastruktury tekstowej komputerów.
Podsumowanie
ASCII to prosty, 7-bitowy standard kodowania znaków, który umożliwił uniwersalną obsługę tekstu w pierwszych komputerach i urządzeniach komunikacyjnych. Chociaż został częściowo zastąpiony przez rozszerzone zestawy i Unicode, jego wpływ jest trwały: wiele narzędzi i formatów tekstowych wciąż opiera się na kompatybilności z ASCII.

Rozszerzony ASCII
ASCII nie posiada znaków diakrytycznych (znaków, które są dodawane do litery, jak kropki (umlauty) nad samogłoskami w języku niemieckim, lub tylda (~) nad "n" dla "ñ" używanego w języku hiszpańskim). Był on przeznaczony tylko dla języka angielskiego i nie działa dobrze dla większości innych języków. Niektóre angielskie słowa zapożyczone z innych języków również używają tych znaków, jak np. resumé (patrz załącznik: angielskie słowa z diakrytykami).
Doprowadziło to do tego, że niektóre systemy używały 8 bitów (pełny bajt) zamiast 7 bitów. Właściwa nazwa dla systemów wykorzystujących 8 bitów to rozszerzony ASCII. Osiem bitów pozwala na użycie 256 znaków. Pierwsze 128 znaków musi być takie same jak w ASCII, a pozostałe są zwykle używane dla liter alfabetycznych z akcentami, np. É, È, Î i Ü. Rozwiązuje to problem języków, które opierają się na alfabecie łacińskim, chociaż nie wszystkie rozszerzone systemy ASCII są takie same. Inne alfabety, takie jak alfabet grecki, cyrylica, wymagają innego zestawu znaków. A niektóre systemy, takie jak te wykorzystujące chińskie znaki, nadal nie działają, ponieważ wykorzystują tysiące znaków. Więc unicode został stworzony, aby mieć jeden wspólny system dla wszystkich języków.
Standard ASCII jest nadal powszechnie stosowany, szczególnie w programach komputerowych i plikach HTML. Do 2010 roku był to standard dla adresów URL. Często strona internetowa, która posiada pola do wprowadzania tekstu, przyjmuje tylko tekst ASCII. Wszelkie specjalne znaczniki dla tekstu pogrubionego lub wyśrodkowanego, itp. będą wyświetlane nieprawidłowo.
Pytania i odpowiedzi
P: Co to jest ASCII?
O: ASCII to tabela znaków dla komputerów, która wykorzystuje kod binarny do obsługi tekstu z użyciem alfabetu angielskiego, liczb i innych popularnych symboli.
P: Co oznacza skrót ASCII?
O: ASCII to skrót od American Standard Code for Information Interchange.
P: Kiedy powstał ASCII?
O: ASCII został opracowany w latach 60-tych.
P: Ile znaków zawiera ten kod?
O: Kod zawiera definicje 128 znaków, którym przypisane są numery od 0 do 127.
P: Ile bitów potrzeba, aby przedstawić znak ASCII?
O: Do przedstawienia znaku ASCII potrzeba 7 cyfr binarnych (bitów).
P: Czy w pliku komputerowym ASCII na każdy znak przypada jeden bajt?
O: Tak, plik komputerowy ASCII używa jednego bajtu na znak, z 8 bitami na bajt.
P: Czy standard ASCII jest nadal powszechnie używany? O: Tak, standard ASCI jest nadal powszechnie stosowany, szczególnie w oprogramowaniu komputerowym i plikach HTML.
Powiązane artykuły
Autor
AlegsaOnline.com ASCII — standard kodowania znaków: definicja, historia i zastosowania Leandro Alegsa
URL: https://pl.alegsaonline.com/art/6475
Źródła
- robelle.com : "ASCII Character Set"
- asciitable.com : "ASCII table & description"