Sieć neuronowa — definicja, działanie i zastosowania
Sieć neuronowa — definicja, działanie i zastosowania: dowiedz się o uczeniu maszynowym, głębokim uczeniu, treningu, przykładach, korzyściach i wyzwaniach.
Sieć neuronowa (zwana również ANN lub sztuczną siecią neuronową) to rodzaj oprogramowania komputerowego, inspirowanego biologicznymi neuronami. Biologiczne mózgi są zdolne do rozwiązywania trudnych problemów, ale każdy neuron jest odpowiedzialny tylko za rozwiązanie bardzo małej części problemu. Podobnie, sieć neuronowa składa się z komórek, które współpracują ze sobą, aby uzyskać pożądany rezultat, chociaż każda pojedyncza komórka jest odpowiedzialna tylko za rozwiązanie niewielkiej części problemu. Jest to jedna z metod tworzenia sztucznie inteligentnych programów.
Sieci neuronowe są przykładem uczenia maszynowego, w którym program może się zmieniać w miarę uczenia się, aby rozwiązać problem. Sieć neuronowa może być trenowana i ulepszana z każdym przykładem, ale im większa sieć neuronowa, tym więcej przykładów potrzebuje, aby działać dobrze, często potrzebując milionów lub miliardów przykładów w przypadku głębokiego uczenia.
Galeria obrazów
6 Obrazy

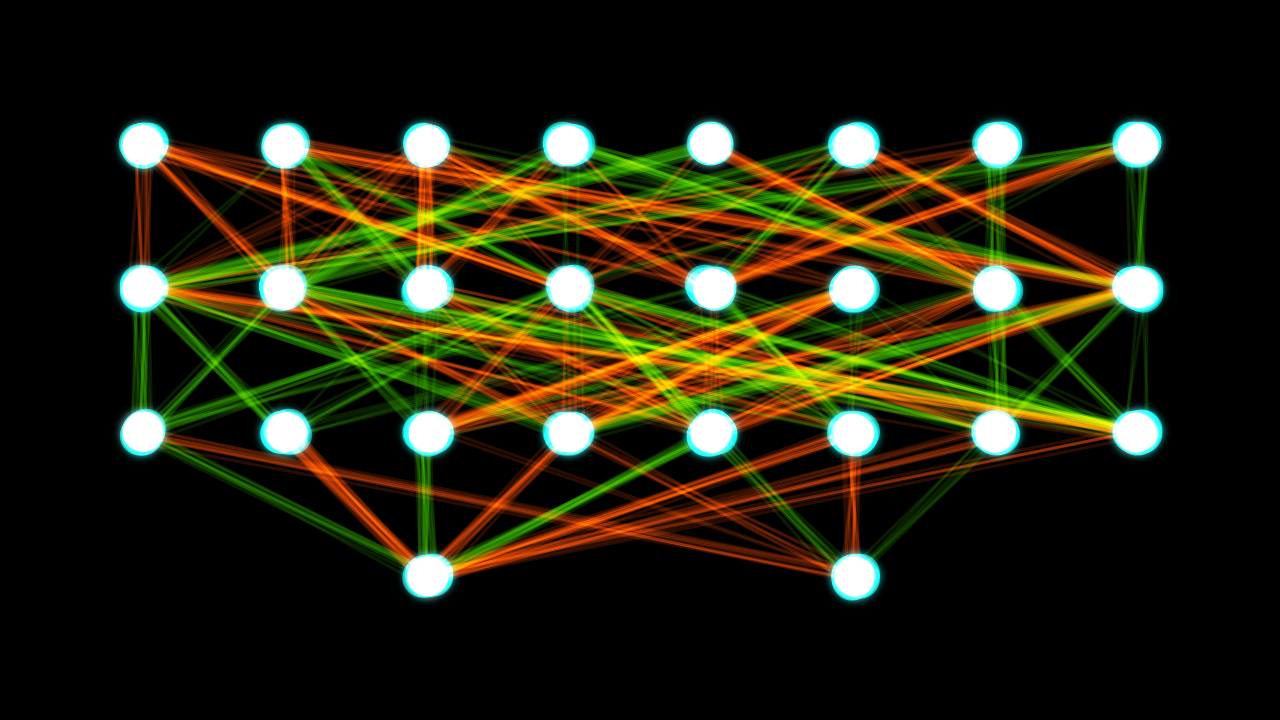



Jak to działa w praktyce?
W najprostszym ujęciu sieć neuronowa przetwarza dane w kilku krokach:
- Wejście: Sieć otrzymuje dane (np. obraz, tekst, sygnał audio).
- Propagacja w przód: Dane przechodzą przez kolejne warstwy „neuronów”, które wykonują proste obliczenia (sumowanie ważone + funkcja aktywacji), a wynik przechodzi do następnej warstwy.
- Porównanie z oczekiwaną odpowiedzią: Na wyjściu obliczana jest różnica między przewidywaniem a poprawną wartością, określana przez funkcję kosztu (loss).
- Uaktualnienie wag: Błąd rozprowadzany jest wstecz (algorytm backpropagation), a wagi synaptyczne są modyfikowane przy użyciu metody optymalizacji (np. gradientu prostego, Adam), aby zmniejszyć błąd.
- Powtarzanie: Proces powtarza się wielokrotnie na dużej liczbie przykładów — dzięki temu sieć „uczy się” rozpoznawać wzorce.
Architektura i podstawowe elementy
- Neuron (perceptron): Element obliczeniowy, który sumuje wejścia pomnożone przez wagi i stosuje funkcję aktywacji (np. ReLU, sigmoid, tanh).
- Warstwy: Wejściowa, ukryte (jedna lub wiele) i wyjściowa. Głębokie sieci mają wiele warstw ukrytych — stąd pojęcie deep learning.
- Wagi i biasy: Parametry sieci, które są uczone podczas treningu.
- Funkcja kosztu: Miara błędu (np. MSE dla regresji, cross-entropy dla klasyfikacji).
- Algorytm optymalizacji: Sposób aktualizacji wag (np. SGD, Adam).
Typy sieci neuronowych
- Sieci jednokierunkowe (Feedforward): Najprostszy typ, typowo używany do klasyfikacji i regresji.
- Splotowe sieci neuronowe (CNN): Dobrze sprawdzają się w analizie obrazów i sygnałów — wykorzystują warstwy splotowe do wykrywania lokalnych wzorców.
- Rekurencyjne sieci neuronowe (RNN): Przeznaczone do danych sekwencyjnych (np. tekst, czasowe serie). Ich rozwinięciami są LSTM i GRU, które lepiej radzą sobie z długimi zależnościami.
- Transformery: Architektura oparta na mechanizmie attention, obecnie dominująca w przetwarzaniu języka naturalnego i coraz częściej stosowana w innych dziedzinach.
- Autoenkodery i GAN: Autoenkodery do redukcji wymiarowości i uczenia reprezentacji; GAN (Generative Adversarial Networks) do generowania nowych danych.
Proces uczenia i praktyczne zagadnienia
- Podział danych: Zwykle dzieli się dane na zbiór treningowy, walidacyjny i testowy.
- Hiperparametry: Wielkość sieci, szybkość uczenia (learning rate), rozmiar batcha, liczba epok — ich dobór ma duży wpływ na wynik.
- Regularizacja: Metody zapobiegające nadmiernemu dopasowaniu (overfitting), np. dropout, L2 (weight decay), wczesne zatrzymanie (early stopping).
- Ocena: Metryki takie jak accuracy, precision, recall, F1, AUC pomagają ocenić efektywność modelu, zależnie od zadania.
- Zapotrzebowanie obliczeniowe: Głębokie sieci często wymagają GPU/TPU i dużych zasobów danych, co wpływa na koszty i czas treningu.
Zastosowania
Sieci neuronowe znalazły zastosowanie w wielu dziedzinach. Przykłady:
- Rozpoznawanie obrazów i wideo: Klasyfikacja obiektów, detekcja, segmentacja — np. w systemach nadzoru, medycynie (analiza obrazów radiologicznych).
- Przetwarzanie języka naturalnego (NLP): Tłumaczenia maszynowe, analiza sentymentu, chatboty, generowanie tekstu (np. modele oparte na transformerach).
- Rozpoznawanie mowy i synteza: Automatyczne systemy rozpoznawania mowy, asystenci głosowi, transkrypcja.
- Rekomendacje: Systemy rekomendacyjne w e-commerce i serwisach streamingowych.
- Analiza danych medycznych i diagnostyka: Wykrywanie chorób, prognozowanie przebiegu chorób, analiza genomu.
- Finanse: Prognozowanie rynków, wykrywanie oszustw, scoring kredytowy.
- Robotyka i sterowanie: Uczenie na podstawie danych sensorycznych, planowanie ruchu, autonomiczne pojazdy.
- Sztuka i kreatywność: Generowanie obrazów, muzyki, stylizacji tekstu (np. tworzenie treści, grafiki generowanej przez sieci).
Zalety i ograniczenia
- Zalety: Umiejętność wykrywania złożonych wzorców, elastyczność — mogą uczyć się reprezentacji bez ręcznego projektowania cech, dobra skalowalność przy dużych zbiorach danych.
- Ograniczenia: Potrzeba dużych ilości danych i mocy obliczeniowej, trudność w interpretacji (problemy z wyjaśnialnością), podatność na błędy i uprzedzenia wynikające z danych treningowych.
Praktyczne wskazówki
- Zaczynaj od prostszego modelu i małego zestawu danych, by zrozumieć problem.
- Dokładnie przygotuj i oczyść dane — jakość danych często decyduje o sukcesie.
- Monitoruj metryki na zbiorze walidacyjnym, aby wykryć przeuczenie.
- Używaj transfer learningu, gdy masz niewiele danych — gotowe modele (np. w przypadku obrazów) można dostroić do konkretnego zadania.
- Pamiętaj o etyce: oceniaj możliwe uprzedzenia, prywatność i skutki wdrożeń w rzeczywistym świecie.
Podsumowanie
Sieci neuronowe to potężne narzędzie uczenia maszynowego, które umożliwia rozwiązywanie złożonych zadań w wielu dziedzinach. Kluczem do skutecznego zastosowania jest zrozumienie ich architektury, odpowiednie przygotowanie danych, właściwy dobór hiperparametrów oraz świadomość ograniczeń i konsekwencji etycznych. Wraz z rozwojem technologii (szybsze układy obliczeniowe, nowe architektury, lepsze algorytmy) sieci neuronowe będą nadal rosły w znaczeniu i zakresie zastosowań.
Przegląd
O sieci neuronowej można myśleć na dwa sposoby. Pierwszy to jak ludzki mózg. Drugi - jak równanie matematyczne.
Sieć zaczyna się od wejścia, trochę jak organ zmysłów. Informacja przepływa następnie przez warstwy neuronów, gdzie każdy neuron jest połączony z wieloma innymi neuronami. Jeśli dany neuron otrzyma wystarczająco dużo bodźców, wysyła wiadomość do każdego innego neuronu, z którym jest połączony poprzez swój akson. Podobnie, sztuczna sieć neuronowa ma warstwę wejściową danych, jedną lub więcej ukrytych warstw klasyfikatorów i warstwę wyjściową. Każdy węzeł w każdej warstwie ukrytej jest połączony z węzłem w następnej warstwie. Gdy węzeł otrzymuje informację, wysyła jej pewną ilość do węzłów, z którymi jest połączony. Ilość ta jest określana przez funkcję matematyczną zwaną funkcją aktywacji, taką jak sigmoida lub tanh.
Myśląc o sieci neuronowej jak o równaniu matematycznym, sieć neuronowa jest po prostu listą operacji matematycznych, które mają być zastosowane do danych wejściowych. Wejściem i wyjściem każdej operacji jest tensor (a dokładniej wektor lub macierz). Każda para warstw jest połączona listą wag. W każdej warstwie znajduje się kilka tensorów. Pojedynczy tensor w warstwie nazywany jest węzłem. Każdy węzeł jest połączony z niektórymi lub wszystkimi węzłami w następnej warstwie za pomocą wagi. Każdy węzeł posiada również listę wartości zwanych biasami. Wartość każdej warstwy jest więc wynikiem funkcji aktywacji wartości bieżącej warstwy (zwanej X) pomnożonej przez wagi.
A k t y w a c j a ( W ( ósemki ) ∗ X + b ( i a s ) ) { {styl Aktywacja(W(ósemki)*X+b(ias))} 
Dla sieci definiowana jest funkcja kosztu. Funkcja straty próbuje oszacować, jak dobrze sieć neuronowa radzi sobie z powierzonym jej zadaniem. Na koniec stosuje się technikę optymalizacji, aby zminimalizować wyjście funkcji kosztu poprzez zmianę wag i biasów sieci. Proces ten nazywany jest treningiem. Trening jest wykonywany jeden mały krok na raz. Po tysiącach kroków sieć jest zazwyczaj w stanie wykonać powierzone jej zadanie całkiem dobrze.
Przykład
Rozważmy program, który sprawdza, czy dana osoba żyje. Jeśli osoba ma puls lub oddycha, program wypisuje komunikat "żyje", w przeciwnym razie wypisuje komunikat "nie żyje". W programie, który nie uczy się z czasem, byłoby to zapisane jako:
Bardzo prosta sieć neuronowa, zbudowana z jednego neuronu, która rozwiązuje ten sam problem, będzie wyglądała tak:
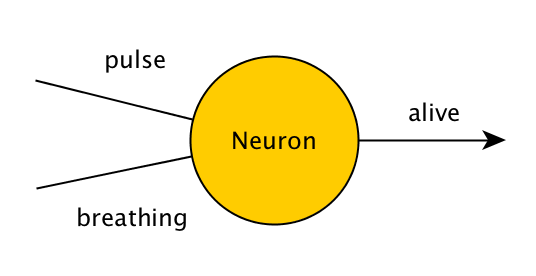
Wartości pulsu, oddychania i życia będą wynosiły 0 lub 1, reprezentując fałsz i prawdę. Tak więc, jeśli ten neuron otrzyma wartości (0,1), (1,0) lub (1,1), powinien wydać 1, a jeśli otrzyma (0,0), powinien wydać 0. Neuron robi to poprzez zastosowanie prostej operacji matematycznej na danych wejściowych - dodaje wszystkie wartości, które otrzymał razem, a następnie dodaje swoją własną ukrytą wartość, która jest nazywana "bias". Na początku, ta ukryta wartość jest losowa, i dostosowujemy ją z czasem, jeśli neuron nie daje nam pożądanego wyjścia.
Jeśli dodamy do siebie wartości takie jak (1,1), możemy otrzymać liczby większe od 1, a przecież chcemy, aby nasze wyjście zawierało się w przedziale od 0 do 1! Aby rozwiązać ten problem, możemy zastosować funkcję, która ograniczy nasze rzeczywiste wyjście do 0 lub 1, nawet jeśli wynik działania neuronu nie mieścił się w tym zakresie. W bardziej skomplikowanych sieciach neuronowych, stosujemy funkcję (taką jak sigmoida) do neuronu, tak aby jego wartość była pomiędzy 0 lub 1 (np. 0.66), a następnie przekazujemy tę wartość do następnego neuronu aż do momentu, gdy potrzebujemy naszego wyjścia.
Metody uczenia się
Istnieją trzy sposoby uczenia się sieci neuronowej: uczenie nadzorowane, uczenie nienadzorowane i uczenie przez wzmocnienie. Wszystkie te metody działają poprzez minimalizowanie lub maksymalizowanie funkcji kosztu, ale każda z nich jest lepsza w określonych zadaniach.
Niedawno zespół badawczy z University of Hertfordshire w Wielkiej Brytanii zastosował uczenie wzmacniające, aby robot humanoidalny iCub nauczył się wypowiadać proste słowa poprzez gaworzenie.
Pytania i odpowiedzi
P: Co to jest sieć neuronowa?
O: Sieć neuronowa (zwana również ANN lub sztuczną siecią neuronową) to rodzaj oprogramowania komputerowego, inspirowanego biologicznymi neuronami. Składa się z komórek, które współpracują ze sobą w celu uzyskania pożądanego wyniku, chociaż każda pojedyncza komórka jest odpowiedzialna za rozwiązanie tylko niewielkiej części problemu.
P: Jak sieć neuronowa ma się do mózgu biologicznego?
O: Biologiczne mózgi są zdolne do rozwiązywania trudnych problemów, ale każdy neuron jest odpowiedzialny za rozwiązanie tylko bardzo małej części problemu. Podobnie sieć neuronowa składa się z komórek, które współpracują ze sobą w celu uzyskania pożądanego rezultatu, chociaż każda pojedyncza komórka jest odpowiedzialna za rozwiązanie tylko niewielkiej części problemu.
P: Jaki typ programu może tworzyć sztucznie inteligentne programy?
O: Sieci neuronowe są przykładem uczenia maszynowego, gdzie program może się zmieniać w miarę jak uczy się rozwiązywać problemy.
P: Jak można trenować i ulepszać z każdym przykładem, aby wykorzystać głębokie uczenie?
O: Sieć neuronową można trenować i poprawiać na każdym przykładzie, ale im większa sieć neuronowa, tym więcej przykładów potrzebuje, aby dobrze działać, często potrzeba milionów lub miliardów przykładów w przypadku głębokiego uczenia.
P: Co jest potrzebne, aby uczenie głębokie odniosło sukces?
O: Aby uczenie głębokie odniosło sukces, potrzebne są miliony lub miliardy przykładów, w zależności od tego, jak duża jest sieć neuronowa.
P: Jak uczenie maszynowe odnosi się do tworzenia sztucznie inteligentnych programów?
O: Uczenie maszynowe odnosi się do tworzenia sztucznie inteligentnych programów, ponieważ pozwala programom zmieniać się w miarę jak uczą się rozwiązywać problemy.
Powiązane artykuły
Autor
AlegsaOnline.com Sieć neuronowa — definicja, działanie i zastosowania Leandro Alegsa
URL: https://pl.alegsaonline.com/art/6353
Źródła
- newscientist.com : "Baby robot learns first words from human teacher"