Algorytmy pamięci podręcznej — definicja i porównanie (LRU, LFU, ARC)
Poznaj definicję i porównanie algorytmów pamięci podręcznej (LRU, LFU, ARC) — zasady działania, zalety, wady i praktyczne zastosowania.
Algorytm pamięci podręcznej to algorytm służący do zarządzania pamięcią podręczną (cache) lub zbiorem buforowanych danych. Gdy pamięć podręczna jest pełna, algorytm decyduje, który element usunąć, aby zwolnić miejsce. Dwa podstawowe wskaźniki jakości działania cache to wskaźnik trafień (hit rate) — jak często żądanie może być obsłużone z pamięci podręcznej — oraz opóźnienie (latencja), czyli latencja opisuje czas dostępu do zbuforowanej pozycji. Algorytmy buforowania są kompromisem pomiędzy maksymalizacją wskaźnika trafień a minimalizacją opóźnienia i kosztów utrzymania informacji pomocniczych (np. metadanych).
Galeria obrazów
7 Obrazy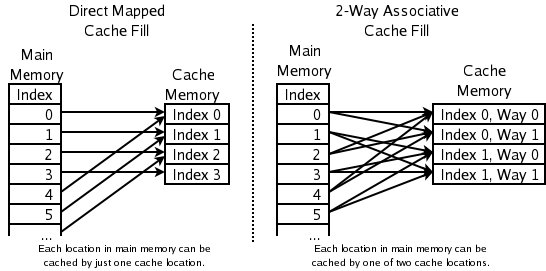



Idea optymalna i ograniczenia praktyczne
Teoretycznie najefektywniejszym algorytmem byłoby zawsze odrzucanie tych danych, które nie będą potrzebne najdłużej w przyszłości — to tzw. optymalny algorytm Belady'ego, często nazywany też algorytmem jasnowidzenia. Ten algorytm wymaga jednak przewidywania przyszłości i dlatego nie jest wykonalny w praktyce. W praktycznych ocenach porównuje się wydajność rzeczywistych algorytmów z tym optymalnym minimum, co pozwala ocenić ich skuteczność na danych rzeczywistych.
Popularne algorytmy i ich cechy
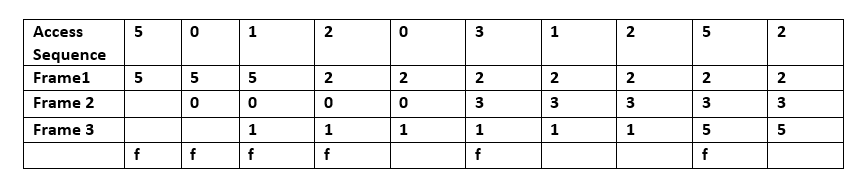
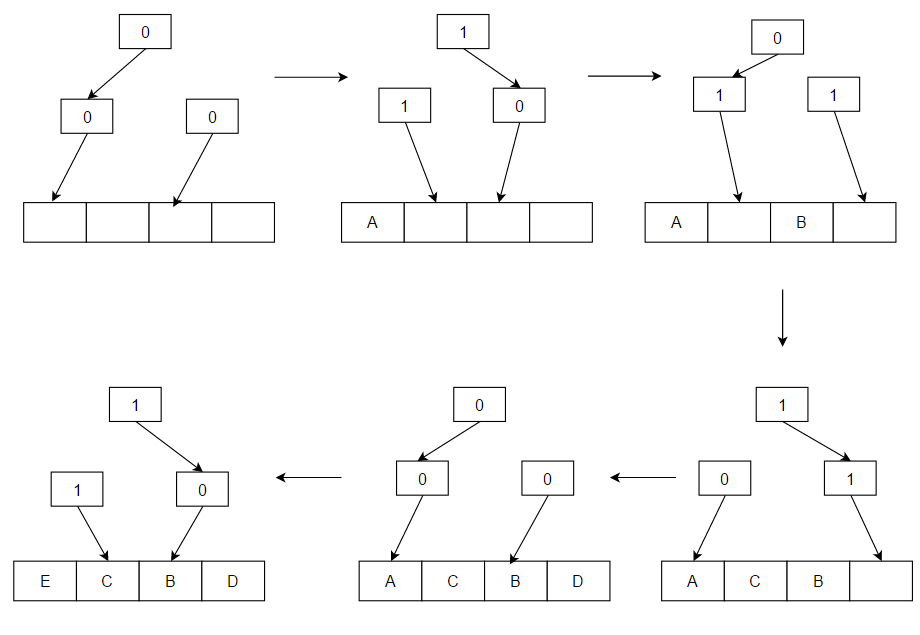
- LRU (Least Recently Used) — usuwa elementy, które były używane najdawniej. LRU zakłada lokalność odnawiania: jeśli coś było użyte niedawno, to istnieje duże prawdopodobieństwo, że będzie użyte ponownie. Implementacje efektywne czasu stałego używają tablicy mieszającej + listy dwukierunkowej (hash + doubly linked list), co daje O(1) dla operacji odczytu i zapisu. LRU może być kosztowny w sprzęcie lub przy bardzo dużych strukturach metadanych. LRU bywa też postrzegane jako rodziną algorytmów buforowania — do tej rodziny należą m.in. 2Q (Theodore Johnson i Dennis Shasha) oraz LRU-K (Pat O'Neil, Betty O'Neil i Gerhard Weikum), które starają się poprawić zachowanie LRU przy różnych wzorcach dostępu.
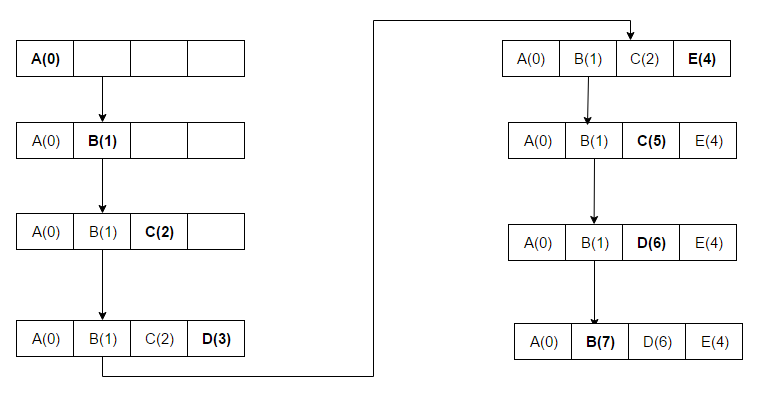
- MRU (Most Recently Used) — usuwa elementy użyte najnowsze. Może mieć sens w sytuacjach, gdzie ostatnio używane elementy są mniej przydatne w przyszłości (np. skanowanie wielu elementów liniowo): wówczas dopiero co użyty element jest najgorszym kandydatem do pozostawienia w cache.
- Pseudo‑LRU (PLRU) — uproszczona wersja LRU, stosowana tam, gdzie dokładne LRU jest za kosztowne (np. w dużych cache CPU). W praktyce PLRU wymaga znacznie mniej bitów stanu (np. jeden bit na linię lub drzewiasta struktura bitów) i zazwyczaj usuwa któryś z mniej niedawno używanych elementów, choć nie zawsze dokładnie najstarszy.
- LFU (Least Frequently Used) — usuwa elementy, które były użyte najrzadziej (liczy częstotliwość użycia). Dobre, gdy kilka pozycji ma stałą, długoterminową popularność. Klasyczne LFU wymaga utrzymywania liczników użyć; bez mechanizmów odświeżania liczników LFU może „uwięzić” elementy, które były kiedyś popularne, lecz już nie są (problem starzenia).
- ARC (Adaptive Replacement Cache) — adaptacyjna polityka łącząca zalety LRU i LFU. ARC utrzymuje dwie listy (krótkoterminową i długoterminową) oraz dodatkowe struktury do automatycznego dopasowania proporcji między nimi, co poprawia ogólną jakość dla zmiennych wzorców dostępu.
- 2Q — rozszerzenie LRU, w którym istnieją dwa poziomy kolejek: krótko- i długoterminowa. Pomaga oddzielić jednorazowe od powtarzalnych odwołań.
- MQ (Multi‑Queue) — algorytm oparty na wielu kolejkach o różnych priorytetach/czasach życia (prace: Y. Zhou, J.F. Philbin i Kai Li). Dobrze radzi sobie z różnorodnością lokalności w jednym obciążeniu.
Algorytmy i struktury w kontekście pamięci CPU
- 2‑drożny zestaw asocjacyjny (2‑way set‑associative) — stosowany w szybkich cache'ach CPU. Adres jest rzutowany na jeden z zestawów, w którym znajdują się dwie (lub więcej) linie; przy wstawianiu wybiera się i usuwa mniej ostatnio używaną z linii tego zestawu. Wymaga jednego bitu na parę linii (np. który z nich był ostatnio używany).
- Direct‑mapped cache — każdemu adresowi odpowiada dokładnie jedna lokalizacja w cache (najprostsza i najszybsza struktura sprzętowa). Przy konflikcie nowa pozycja po prostu zastępuje poprzednią.
Dodatkowe czynniki i rozszerzenia polityk buforowania
- Koszt pozyskania elementu: warto zachować elementy, których ponowne pobranie jest kosztowne (czasowo lub zasobowo). W tym celu stosuje się polityki kosztowo‑świadome (np. GreedyDual lub GDSF), które uwzględniają koszt, częstotliwość i rozmiar.
- Różne rozmiary obiektów: gdy elementy mają różne rozmiary, trzeba uwzględnić przyjętą metrykę (np. miejsce zajmowane w pamięci) — czasem korzystniejsze jest usunięcie jednego dużego obiektu, aby zrobić miejsce dla wielu mniejszych. Zwykłe LRU nie bierze tego pod uwagę; do tego celu stosuje się rozszerzenia ważone rozmiarem.
- Wygaśnięcie (TTL) i dane czasowe: niektóre cache (np. DNS, cache HTTP, przeglądarki) przechowują dane, które mają określony czas ważności. W takim przypadku elementy mogą być usuwane po wygaśnięciu niezależnie od polityki zastępowania; przy odpowiednio małej pojemności cache może być w pełni obsługiwany jedynie przez mechanizmy TTL.
- Polityki zapisu: dla cache'ów zapisów (write caches) istotne są polityki write‑through vs write‑back oraz polityki zapisu zachowujące spójność z pamięcią źródłową (flush, write‑coalescing itp.).
Wydajność i złożoność implementacji
- LRU z hash + lista dwukierunkowa: O(1) dla odczytu i zapisu, wymaga dodatkowej pamięci na wskaźniki.
- LFU: wymaga liczników; efektywne implementacje (np. z listami częstotliwości) potrafią osiągnąć amortyzowany O(1), ale są bardziej złożone niż LRU.
- PLRU i struktury sprzętowe: niższe koszty pamięci i prostsza logika, lecz gorsza dokładność wyboru do usunięcia.
- Adaptacyjne algorytmy (ARC, MQ, 2Q): zwykle lepsze dopasowanie do mieszanych wzorców, ale wyższa złożoność implementacyjna i koszty metadanych.
Jak wybrać algorytm?
- Jeśli obowiązuje silna lokalność czasowa (to, co było użyte niedawno, z dużym prawdopodobieństwem będzie użyte ponownie) — LRU jest prostym i skutecznym wyborem.
- Gdy liczy się długoterminowa popularność (gorące obiekty) — warto rozważyć LFU lub hybrydy (ARC, MQ).
- Gdy koszt pobrania danych jest wysoki — użyj polityki kosztowo‑świadomej (np. GDSF).
- Gdy obiekty mają bardzo różne rozmiary — stosuj polityki ważone rozmiarem lub specjalne strategie zarządzania miejscem.
- W systemach o krytycznych wymaganiach czasu dostępu (np. CPU cache) wybiera się uproszczone, szybsze polityki (PLRU, 2‑way, direct‑mapped).
Spójność i wieloserwerowe środowiska
Różne algorytmy służą także do utrzymania spójności pamięci podręcznej — chodzi tu o sytuacje, gdy wiele niezależnych pamięci podręcznych obsługuje te same dane (np. wiele serwerów aplikacyjnych lub replik baz danych). Typowe techniki to: invalidacja (unieważnianie wpisów), propagacja aktualizacji, mechanizmy write‑through/write‑back, protokoły directory‑based i snooping w sprzęcie. Wybór strategii spójności zależy od wymagań dotyczących opóźnień, przepustowości i modelu spójności (np. silna spójność vs spójność ostateczna).
Podsumowując: nie ma uniwersalnego najlepszego algorytmu — wybór zależy od charakterystyki dostępu (lokalność czasowa vs częstotliwość), kosztu pobierania danych, rozmiarów obiektów oraz ograniczeń sprzętowych. W praktyce często stosuje się algorytmy adaptacyjne (np. ARC, MQ) lub hybrydowe, które próbują łączyć zalety LRU i LFU oraz uwzględniać dodatkowe kryteria (koszt, rozmiar, TTL).

Pytania i odpowiedzi
P: Co to jest Algorytm Cache?
O: Algorytm Cache to algorytm służący do zarządzania pamięcią podręczną lub grupą danych. Decyduje on, który element powinien zostać usunięty z pamięci podręcznej, gdy jest ona pełna.
P: Co to jest współczynnik trafień?
O: Współczynnik trafień opisuje, jak często żądanie może zostać obsłużone z cache.
P: Co to jest latencja?
A: Latencja opisuje, jak długo można uzyskać element z bufora.
P: Co to jest optymalny algorytm Belady'ego?
O: Optymalny algorytm Belady'ego, znany również jako algorytm jasnowidza, jest wydajnym algorytmem buforowania, który zawsze odrzuca informacje, które nie będą potrzebne przez najdłuższy czas w przyszłości. Tego wyniku nie da się na ogół zastosować w praktyce, ponieważ wymaga on przewidywania, co będzie potrzebne w dalekiej przyszłości.
P: Jak działa zasada LRU (Least Recently Used)?
O: LRU usuwa w pierwszej kolejności ostatnio używane elementy i wymaga śledzenia, co było używane kiedy, poprzez użycie "bitów wieku" dla każdej linii pamięci podręcznej i śledzenie, która z nich była ostatnio używana na podstawie bitów wieku. Za każdym razem, gdy linia pamięci podręcznej jest używana, wiek wszystkich innych linii pamięci podręcznej jest odpowiednio zmieniany.
P: Jak działa funkcja Most Recently Used (MRU)?
O: MRU usuwa w pierwszej kolejności ostatnio używane elementy i ten mechanizm buforowania jest powszechnie stosowany w pamięci podręcznej baz danych.
P: Jakie inne algorytmy istnieją, aby utrzymać spójność pamięci podręcznej?
O: Istnieją różne algorytmy utrzymywania spójności pamięci podręcznej, gdy wiele niezależnych pamięci podręcznych jest używanych dla wspólnych danych, takich jak wiele serwerów baz danych aktualizujących jeden wspólny plik danych.
Powiązane artykuły
Autor
AlegsaOnline.com Algorytmy pamięci podręcznej — definicja i porównanie (LRU, LFU, ARC) Leandro Alegsa
URL: https://pl.alegsaonline.com/art/15882
Źródła
- usenix.org : usenix.org/legacy/events/fast03/tech/full_papers/megiddo/megiddo.pdf
- usenix.org : usenix.org