Mikroarchitektura procesora — definicja, elementy i zasady działania
Poznaj mikroarchitekturę procesora — definicję, kluczowe elementy i zasady działania. Praktyczne wyjaśnienia, schematy i przykłady dla inżynierów i pasjonatów.
W inżynierii komputerowej mikroarchitektura (czasami oznaczana skrótem µarch lub uarch) jest opisem obwodu elektrycznego komputera, jednostki centralnej lub cyfrowego procesora sygnałowego, który jest wystarczający do pełnego opisu działania sprzętu.
Naukowcy używają terminu "organizacja komputera", natomiast ludzie z branży komputerowej częściej mówią "mikroarchitektura". Mikroarchitektura i architektura zestawu instrukcji (ISA) stanowią razem dziedzinę architektury komputerowej.
Galeria obrazów
1 Obraz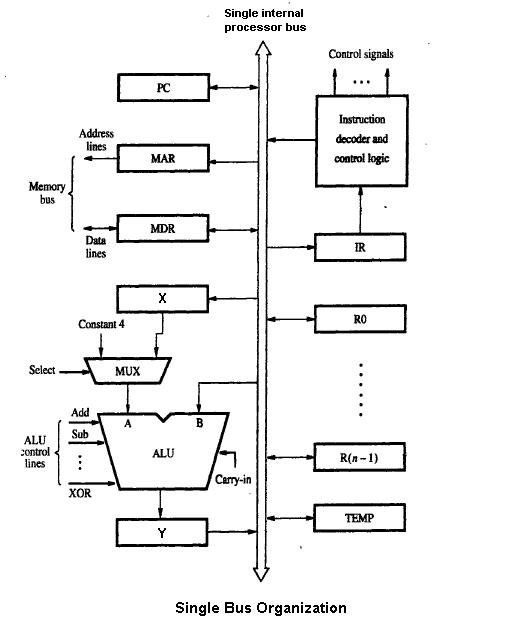
Co obejmuje mikroarchitektura?
Mikroarchitektura opisuje wewnętrzną budowę i sposób działania procesora na poziomie implementacji. Obejmuje zarówno elementy sprzętowe, jak i mechanizmy sterujące, które razem realizują instrukcje zdefiniowane przez ISA. Najważniejsze składniki mikroarchitektury to m.in.:
- Rejestry — małe, szybkie miejsca przechowywania wewnątrz procesora.
- Jednostka arytmetyczno‑logiczna (ALU) — wykonuje operacje arytmetyczne i logiczne.
- Jednostki wykonawcze — różne bloki odpowiedzialne za całkowite, zmiennoprzecinkowe, wektorowe lub specjalne operacje.
- Jednostka sterująca — zarządza przepływem instrukcji i danymi, może być oparta na mikroprogramie (microcode) lub być sprzętowo zdefiniowana.
- Potok (pipeline) — podział przetwarzania instrukcji na fazy (pobranie, dekodowanie, wykonanie, dostęp do pamięci, zapis wyniku) umożliwiający równoległą pracę wielu instrukcji.
- Pamięć podręczna (cache) — warstwy szybkiej pamięci między procesorem a pamięcią główną, istotne dla wydajności.
- Mechanizmy przewidywania skoków (branch prediction) — zmniejszają koszty błędnych skoków w potoku.
- Zarządzanie pamięcią — jednostki translacji adresów (MMU), buforowanie i protokoły spójności w wielordzeniowych systemach.
- Schematy równoległości — superskalarność, wielordzeniowość, SMT/Hyper‑Threading, wykonanie poza kolejnością (out‑of‑order).
Główne zasady działania
Mikroarchitektura realizuje instrukcje ISA przez sekwencję działań skoordynowanych pomiędzy opisanymi komponentami. Kilka kluczowych zasad to:
- Dzielenie na etapy (pipelining) — każda instrukcja przechodzi kolejne etapy, a różne instrukcje wykonywane są równocześnie w różnych etapach, co zwiększa przepustowość.
- Równoległe jednostki wykonawcze — wiele instrukcji może być jednocześnie wykonywanych przez różne jednostki, co wymaga mechanizmów harmonizacji wyników.
- Wykonywanie poza kolejnością — procesor może wykonywać dostępne instrukcje niezależnie od ich oryginalnej kolejności w programie, by lepiej wykorzystać zasoby; konieczne są wtedy mechanizmy przywracania porządku i obsługi wyjątków.
- Przewidywanie i spekulacja — procesor przewiduje wyniki skoków lub warunków i spekuluje wykonanie instrukcji, a w razie błędu wycofuje efekty.
- Hierarchia pamięci — dąży się do minimalizacji opóźnień przez lokalizowanie danych bliżej wykonawczych jednostek (rejestry → cache → pamięć główna → pamięć masowa).
- Minimalizacja zależności — techniki, takie jak renaming rejestrów czy kolejki ładowań/zapisań, redukują konflikty między instrukcjami.
Rodzaje implementacji
Mikroarchitektury można realizować na różne sposoby:
- Sprzętowo sterowane (hardwired) — logika sterująca jest zrealizowana bezpośrednio układami cyfrowymi, co daje szybkie działanie.
- Mikrokodowane — złożone instrukcje są realizowane przez sekwencje krótszych mikroinstrukcji zapisanych w pamięci mikroprogramu; łatwiejsze do modyfikacji, ale mogą być wolniejsze.
- RISC vs CISC — style projektowe: RISC (proste, krótkie instrukcje, duży nacisk na potok) i CISC (bogatszy zestaw instrukcji, często realizowany mikrokodowo). W praktyce współczesne procesory łączą cechy obu podejść.
Wyzwania i kompromisy projektowe
Projektowanie mikroarchitektury to ciąg kompromisów:
- Wydajność vs złożoność — zaawansowane techniki (OOO, predykcja gałęzi) zwiększają wydajność, ale komplikują projekt i weryfikację.
- Wydajność vs zużycie energii — wyższa częstotliwość i większa równoległość rosną kosztem poboru mocy i emisji ciepła.
- Koszt produkcji vs funkcjonalność — dodawanie jednostek wykonawczych, większych cache'ów i złożonych mechanizmów kontroli zwiększa koszt chipu.
- Bezpieczeństwo — techniki spekulacyjne i współdzielenie zasobów mogą ujawnić dane (przykłady: Spectre, Meltdown), co wymaga poprawek w mikroarchitekturze i oprogramowaniu.
Narzędzia i walidacja
Projekt mikroarchitektury wymaga symulacji, emulacji i intensywnych testów. Inżynierowie używają:
- symulatorów cyklicznych (cycle‑accurate) do analizy wydajności,
- narzędzi do formalnej weryfikacji poprawności,
- FPGA do prototypowania,
- benchmarków i profilerów do oceny rzeczywistego zachowania w systemie.
Przykłady i zastosowania
Mikroarchitektura jest kluczowa w procesorach ogólnego przeznaczenia (np. serwery, komputery osobiste, urządzenia mobilne), w układach do przetwarzania sygnałów, w mikrokontrolerach i w jednostkach specjalizowanych (GPU, NPU). Różne rodziny procesorów (np. x86, ARM) dzielą ISA, lecz mogą mieć bardzo różne mikroarchitektury — od prostych, energooszczędnych rdzeni po bardzo złożone, wielordzeniowe układy serwerowe.
Podsumowanie
Mikroarchitektura to szczegółowy opis wewnętrznej organizacji procesora, opisujący jak sprzęt realizuje instrukcje z ISA. To pole łączące elektronikę, projektowanie układów cyfrowych i optymalizację wydajności oraz zużycia energii. Rozumienie mikroarchitektury pomaga wyjaśnić, dlaczego różne procesory o tej samej architekturze zestawu instrukcji mogą mieć odmienną wydajność, efektywność energetyczną i koszty.
Pochodzenie terminu
Komputery wykorzystują mikroprogramowanie logiki sterowania od lat 50-tych. CPU dekoduje instrukcje i wysyła sygnały odpowiednimi ścieżkami za pomocą przełączników tranzystorowych. Bity wewnątrz słów mikroprogramu sterowały procesorem na poziomie sygnałów elektrycznych.
Termin: mikroarchitektura był używany do opisania jednostek, które były kontrolowane przez słowa mikroprogramu, w przeciwieństwie do terminu: "architektura", która była widoczna i udokumentowana dla programistów. Podczas gdy architektura zazwyczaj musiała być kompatybilna pomiędzy generacjami sprzętu, leżąca u jej podstaw mikroarchitektura mogła być łatwo zmieniana.
Związek z architekturą zestawu instrukcji
Mikroarchitektura jest związana z architekturą zestawu instrukcji, ale nie jest z nią tożsama. Architektura zestawu instrukcji jest bliska modelowi programowania procesora widzianemu przez programistę języka asemblerowego lub autora kompilatora, który obejmuje model wykonania, rejestry procesora, tryby adresowania pamięci, formaty adresów i danych itp. Mikroarchitektura (lub organizacja komputera) jest głównie strukturą niższego poziomu i dlatego zarządza dużą liczbą szczegółów, które są ukryte w modelu programowania. Opisuje ona wewnętrzne części procesora i to, jak współpracują one ze sobą w celu realizacji specyfikacji architektonicznej.
Elementami mikroarchitektonicznymi może być wszystko, od pojedynczych bramek logicznych, przez rejestry, tablice wyliczające, multipleksery, liczniki itp. do kompletnych jednostek ALU, FPU, a nawet większych elementów. Poziom obwodów elektronicznych może być z kolei podzielony na szczegóły na poziomie tranzystorów, takie jak to, które podstawowe struktury budowy bramek są używane i jakie typy implementacji logiki (statyczne/dynamiczne, liczba faz, itp.) są wybierane, oprócz rzeczywistego projektu logicznego użytego do ich budowy.
Kilka ważnych punktów:
- Pojedyncza mikroarchitektura, szczególnie jeśli zawiera mikrokod, może być użyta do implementacji wielu różnych zestawów instrukcji, poprzez zmianę magazynu sterowania. Może to być jednak dość skomplikowane, nawet jeśli jest uproszczone przez mikrokod i/lub struktury tabelaryczne w ROM-ach lub PLA-ach.
- Dwie maszyny mogą mieć tę samą mikroarchitekturę, a więc ten sam schemat blokowy, ale zupełnie różne implementacje sprzętowe. Zarządza to zarówno poziomem układów elektronicznych, jak i jeszcze bardziej fizycznym poziomem produkcji (zarówno układów scalonych, jak i elementów dyskretnych).
- Maszyny z różnymi mikroarchitekturami mogą mieć tę samą architekturę zestawu instrukcji, a więc obie są zdolne do wykonywania tych samych programów. Nowe mikroarchitektury i/lub rozwiązania układowe, wraz z postępem w produkcji półprzewodników, są tym, co pozwala nowszym generacjom procesorów osiągać wyższą wydajność.
Uproszczone opisy
Bardzo uproszczony opis wysokiego poziomu - powszechny w marketingu - może pokazywać tylko dość podstawowe cechy, takie jak szerokość magistrali, wraz z różnymi typami jednostek wykonawczych i innych dużych systemów, takich jak przewidywanie rozgałęzień i pamięci podręczne, przedstawionych jako proste bloki - być może z zaznaczonymi niektórymi ważnymi atrybutami lub cechami. Niektóre szczegóły dotyczące struktury potoku (jak pobieranie, dekodowanie, przydzielanie, wykonywanie, zapisywanie z powrotem) mogą być czasami również zawarte.
Aspekty mikroarchitektury
Potokowa ścieżka danych jest obecnie najczęściej stosowaną konstrukcją ścieżki danych w mikroarchitekturze. Technika ta jest używana w większości nowoczesnych mikroprocesorów, mikrokontrolerów i procesorów DSP. Architektura potokowa pozwala wielu instrukcjom nakładać się w czasie wykonywania, podobnie jak w linii montażowej. Rurociąg zawiera kilka różnych etapów, które są fundamentalne w projektach mikroarchitektury. Niektóre z tych etapów obejmują pobieranie instrukcji, dekodowanie instrukcji, wykonywanie i zapisywanie z powrotem. Niektóre architektury zawierają również inne etapy, takie jak dostęp do pamięci. Projektowanie potoków jest jednym z centralnych zadań mikroarchitektonicznych.
Jednostki wykonawcze są również istotne dla mikroarchitektury. Jednostki wykonawcze obejmują jednostki arytmetyczno-logiczne (ALU), jednostki zmiennoprzecinkowe (FPU), jednostki load/store i przewidywanie rozgałęzień. Jednostki te wykonują operacje lub obliczenia procesora. Wybór liczby jednostek wykonawczych, ich opóźnienia i przepustowości są ważnymi zadaniami projektowania mikroarchitektonicznego. Rozmiar, opóźnienie, przepustowość i łączność pamięci w ramach systemu są również decyzjami mikroarchitektonicznymi.
Decyzje projektowe na poziomie systemu, takie jak to, czy włączyć urządzenia peryferyjne, takie jak kontrolery pamięci, można uznać za część procesu projektowania mikroarchitektonicznego. Obejmuje to decyzje dotyczące poziomu wydajności i łączności tych urządzeń peryferyjnych.
W przeciwieństwie do projektowania architektonicznego, gdzie głównym celem jest określony poziom wydajności, projektowanie mikroarchitektoniczne zwraca baczniejszą uwagę na inne ograniczenia. Należy zwrócić uwagę na takie zagadnienia jak:
- Powierzchnia chipa/koszt.
- Pobór mocy.
- Złożoność logiczna.
- Łatwość podłączenia.
- Produkcyjność.
- Łatwość debugowania.
- Testowalność.
Koncepcje mikroarchitektoniczne
Ogólnie rzecz biorąc, wszystkie procesory, mikroprocesory jednoukładowe lub wieloukładowe, uruchamiają programy, wykonując następujące czynności:
- Przeczytaj instrukcję i rozszyfruj ją.
- Znajdź wszelkie powiązane dane, które są potrzebne do przetworzenia instrukcji.
- Wykonać polecenie.
- Wypisz wyniki.
Komplikacją tej prosto wyglądającej serii kroków jest fakt, że hierarchia pamięci, która obejmuje buforowanie, pamięć główną i nieulotną pamięć masową, taką jak dyski twarde, (gdzie znajdują się instrukcje programu i dane) zawsze była wolniejsza niż sam procesor. Krok (2) często wprowadza opóźnienie (w terminologii CPU często nazywane "przeciągnięciem"), podczas gdy dane docierają przez magistralę komputera. Wiele badań poświęcono konstrukcjom, które w jak największym stopniu unikają tych opóźnień. Przez lata głównym celem projektantów było równoległe wykonywanie większej liczby instrukcji, zwiększając w ten sposób efektywną szybkość wykonywania programu. Te wysiłki wprowadziły skomplikowane struktury logiczne i układowe. W przeszłości takie techniki mogły być implementowane tylko na drogich komputerach typu mainframe lub superkomputerach ze względu na ilość potrzebnych do tego obwodów. Wraz z postępem w produkcji półprzewodników, coraz więcej z tych technik można było zaimplementować na pojedynczym chipie półprzewodnikowym.
Poniżej znajduje się przegląd technik mikroarchitektonicznych, które są powszechnie stosowane w nowoczesnych procesorach.
Wybór zestawu instrukcji
Wybór architektury zestawu instrukcji w znacznym stopniu wpływa na złożoność implementacji urządzeń o wysokiej wydajności. Przez lata projektanci komputerów robili wszystko, aby uprościć zestawy instrukcji, aby umożliwić implementacje o wyższej wydajności, oszczędzając wysiłek i czas projektantów na funkcje poprawiające wydajność, zamiast marnować go na złożoność zestawu instrukcji.
Projektowanie zestawów instrukcji rozwinęło się od typów CISC, RISC, VLIW, EPIC. Architektury, które zajmują się paralelizmem danych to SIMD i Vectors.
Łączenie instrukcji w potoki
Jedną z pierwszych i najpotężniejszych technik zwiększania wydajności jest wykorzystanie potoku instrukcji. Wczesne konstrukcje procesorów wykonywały wszystkie powyższe kroki na jednej instrukcji przed przejściem do następnej. Duża część obwodów procesora pozostawała bezczynna na każdym etapie; na przykład, obwody dekodujące instrukcje były bezczynne podczas wykonywania instrukcji i tak dalej.
Linie potokowe zwiększają wydajność, pozwalając wielu instrukcjom pracować w procesorze w tym samym czasie. W tym samym podstawowym przykładzie procesor zacząłby dekodować (krok 1) nową instrukcję, podczas gdy poprzednia czekała na wyniki. Dzięki temu w jednym czasie mogą być "w locie" nawet cztery instrukcje, co sprawia, że procesor działa cztery razy szybciej. Chociaż wykonanie każdej instrukcji trwa tak samo długo (nadal są cztery kroki), procesor jako całość "wycofuje" instrukcje znacznie szybciej i może pracować z dużo wyższą prędkością zegara.
Cache
Udoskonalenia w produkcji układów scalonych pozwoliły na umieszczenie większej ilości obwodów na jednym chipie, a projektanci zaczęli szukać sposobów na ich wykorzystanie. Jednym z najczęstszych sposobów było dodawanie coraz większej ilości pamięci cache na chipie. Pamięć podręczna jest bardzo szybką pamięcią, do której dostęp można uzyskać w ciągu kilku cykli w porównaniu do tego, co jest potrzebne do rozmowy z pamięcią główną. Procesor zawiera kontroler pamięci podręcznej, który automatyzuje odczyt i zapis z pamięci podręcznej, jeśli dane są już w pamięci podręcznej, to po prostu "pojawia się", podczas gdy jeśli nie jest, procesor jest "zatrzymany", podczas gdy kontroler pamięci podręcznej czyta go w.
W konstrukcjach RISC zaczęto dodawać pamięć podręczną w połowie lub pod koniec lat 80-tych, często o łącznej wielkości zaledwie 4 KB. Liczba ta rosła z czasem i obecnie typowe procesory mają około 512 KB, podczas gdy bardziej wydajne procesory mają 1 lub 2, a nawet 4, 6, 8 lub 12 MB, zorganizowane na wielu poziomach hierarchii pamięci. Ogólnie rzecz biorąc, więcej pamięci podręcznej oznacza większą szybkość.
Cache i potoki idealnie do siebie pasowały. Wcześniej nie było sensu budować potoku, który mógłby działać szybciej niż opóźnienie dostępu do pamięci podręcznej poza chipem. Użycie zamiast tego pamięci cache on-chip oznaczało, że potok mógł działać z prędkością opóźnienia dostępu do pamięci cache, czyli przez znacznie mniejszy okres czasu. Pozwoliło to na zwiększenie częstotliwości pracy procesorów w znacznie szybszym tempie niż w przypadku pamięci off-chip.
Przewidywanie rozgałęzień i wykonywanie spekulacyjne
Spiętrzenia w potoku i przepłukiwanie spowodowane rozgałęzieniami to dwie główne rzeczy uniemożliwiające osiągnięcie wyższej wydajności poprzez równoległość na poziomie instrukcji. Od czasu, gdy dekoder instrukcji procesora stwierdzi, że napotkał instrukcję warunkowego rozgałęzienia do czasu, gdy decydująca wartość rejestru skoków może zostać odczytana, potok może utknąć w martwym punkcie na kilka cykli. Średnio, co piąta wykonywana instrukcja jest rozgałęzieniem, więc jest to duża ilość przestojów. Jeśli rozgałęzienie zostanie wykonane, jest jeszcze gorzej, ponieważ wtedy wszystkie kolejne instrukcje, które były w potoku muszą zostać przepłukane.
Techniki takie jak przewidywanie rozgałęzień i wykonywanie spekulatywne są używane do redukcji tych kar za rozgałęzienia. Przewidywanie rozgałęzień polega na tym, że sprzęt zgaduje, czy dane rozgałęzienie zostanie wykonane. Domysły te pozwalają sprzętowi na prefetchowanie instrukcji bez czekania na odczyt rejestru. Wykonywanie spekulatywne jest kolejnym ulepszeniem, w którym kod wzdłuż przewidywanej ścieżki jest wykonywany zanim wiadomo, czy rozgałęzienie powinno zostać wykonane czy nie.
Wykonanie poza kolejnością
Dodanie pamięci podręcznej zmniejsza częstotliwość lub czas trwania przestojów spowodowanych oczekiwaniem na dane, które mają być pobrane z głównej hierarchii pamięci, ale nie eliminuje całkowicie tych przestojów. We wczesnych projektach pominięcie pamięci podręcznej zmuszało kontroler pamięci podręcznej do zatrzymania procesora i czekania. Oczywiście w programie może być jakaś inna instrukcja, której dane są dostępne w pamięci podręcznej w tym momencie. Wykonywanie poza kolejnością pozwala tej gotowej instrukcji być przetwarzaną, podczas gdy starsza instrukcja czeka w pamięci podręcznej, a następnie zmienia kolejność wyników, aby sprawić wrażenie, że wszystko wydarzyło się w zaprogramowanej kolejności.
Superskalar
Nawet przy całej tej dodatkowej złożoności i bramkach potrzebnych do obsługi opisanych powyżej koncepcji, usprawnienia w produkcji półprzewodników wkrótce pozwoliły na zastosowanie jeszcze większej liczby bramek logicznych.
W powyższym schemacie procesor przetwarza części pojedynczej instrukcji na raz. Programy komputerowe mogłyby być wykonywane szybciej, gdyby wiele instrukcji było przetwarzanych jednocześnie. To właśnie osiągają procesory superskalarne, poprzez replikację jednostek funkcjonalnych, takich jak ALU. Replikacja jednostek funkcjonalnych stała się możliwa dopiero wtedy, gdy powierzchnia układu scalonego (zwanego czasem "matrycą") procesora jednoprocesorowego przestała przekraczać granice tego, co można było wyprodukować w sposób niezawodny. Pod koniec lat 80. na rynku zaczęły pojawiać się konstrukcje superskalarne.
W nowoczesnych projektach często spotyka się dwie jednostki ładujące, jedną przechowującą (wiele instrukcji nie ma wyników do przechowywania), dwie lub więcej jednostek obliczeniowych dla liczb całkowitych, dwie lub więcej jednostek zmiennoprzecinkowych i często jednostkę SIMD jakiegoś rodzaju. Logika wydawania instrukcji staje się coraz bardziej złożona poprzez wczytywanie ogromnej listy instrukcji z pamięci i przekazywanie ich do różnych jednostek wykonawczych, które są w tym momencie bezczynne. Wyniki są następnie zbierane i ponownie porządkowane na końcu.
Zmiana nazwy rejestru
Zmiana nazwy rejestru odnosi się do techniki używanej w celu uniknięcia niepotrzebnego szeregowego wykonywania instrukcji programu z powodu ponownego użycia tych samych rejestrów przez te instrukcje. Załóżmy, że mamy dwie grupy instrukcji, które będą używać tego samego rejestru, jeden zestaw instrukcji jest wykonywany jako pierwszy, aby pozostawić rejestr drugiemu zestawowi, ale jeśli drugi zestaw jest przypisany do innego podobnego rejestru, oba zestawy instrukcji mogą być wykonywane równolegle.
Wieloprocesowość i wielowątkowość
Ze względu na rosnącą różnicę pomiędzy częstotliwością pracy procesora a czasem dostępu do pamięci DRAM, żadna z technik zwiększających równoległość na poziomie instrukcji (ILP) w ramach jednego programu nie była w stanie przezwyciężyć długich przestojów (opóźnień), które występowały, gdy dane musiały być pobierane z pamięci głównej. Dodatkowo, duża liczba tranzystorów i wysokie częstotliwości pracy wymagane przez bardziej zaawansowane techniki ILP wymagały rozpraszania energii na poziomie, którego nie dało się już tanio schłodzić. Z tych powodów, nowsze generacje komputerów zaczęły wykorzystywać wyższe poziomy równoległości, które istnieją poza pojedynczym programem lub wątkiem programu.
Ten trend jest czasami znany jako "throughput computing". Idea ta wywodzi się z rynku mainframe, gdzie przetwarzanie transakcji online kładło nacisk nie tylko na szybkość wykonania jednej transakcji, ale także na zdolność do obsługi dużej liczby transakcji w tym samym czasie. W ostatniej dekadzie, gdy znacznie wzrosła liczba aplikacji opartych na transakcjach, takich jak routing sieciowy i obsługa stron internetowych, przemysł komputerowy ponownie położył nacisk na kwestie wydajności i przepustowości.
Jedną z technik osiągania tej równoległości są systemy wieloprocesorowe, czyli systemy komputerowe z wieloma procesorami. W przeszłości było to zarezerwowane dla high-endowych mainframe'ów, ale teraz małe serwery (2-8) wieloprocesorowe stały się powszechne na rynku małych firm. Dla dużych korporacji powszechne są wieloprocesory o dużej skali (16-256). Od lat 90. pojawiły się nawet komputery osobiste z wieloma procesorami.
Postęp w technologii półprzewodnikowej zmniejszył rozmiar tranzystorów; pojawiły się wielordzeniowe procesory, w których wiele procesorów jest zaimplementowanych na tym samym układzie krzemowym. Początkowo były stosowane w układach przeznaczonych na rynki wbudowane, gdzie prostsze i mniejsze procesory pozwalały na umieszczenie wielu instancji na jednym kawałku krzemu. Do 2005 r. technologia półprzewodnikowa umożliwiła masową produkcję układów CMP z dwoma procesorami CMP dla komputerów stacjonarnych klasy high-end. Niektóre konstrukcje, takie jak UltraSPARC T1, wykorzystywały prostsze (skalarne, in-order) projekty, aby zmieścić więcej procesorów na jednym kawałku krzemu.
Ostatnio inną techniką, która stała się bardziej popularna, jest wielowątkowość. W wielowątkowości, gdy procesor musi pobrać dane z wolnej pamięci systemowej, zamiast czekać na ich przybycie, procesor przełącza się do innego programu lub wątku programu, który jest gotowy do wykonania. Chociaż nie przyspiesza to konkretnego programu/wątku, zwiększa ogólną przepustowość systemu poprzez skrócenie czasu bezczynności procesora.
Koncepcyjnie wielowątkowość jest równoważna przełącznikowi kontekstu na poziomie systemu operacyjnego. Różnica polega na tym, że wielowątkowy procesor może wykonać przełączenie wątku w jednym cyklu procesora zamiast setek lub tysięcy cykli procesora, których normalnie wymaga przełączenie kontekstu. Osiąga się to poprzez replikację sprzętu stanowego (takiego jak plik rejestrów i licznik programu) dla każdego aktywnego wątku.
Kolejnym usprawnieniem jest wielowątkowość symultaniczna. Technika ta pozwala procesorom superskalarnym na jednoczesne wykonywanie instrukcji z różnych programów/wątków w tym samym cyklu.
Powiązane strony
- Mikroprocesor
- Mikrokontroler
- Procesor wielordzeniowy
- Cyfrowy procesor sygnałowy
- Konstrukcja procesora
- Datapath
- równoległość na poziomie instrukcji (ILP)
Pytania i odpowiedzi
P: Co to jest mikroarchitektura?
O: Mikroarchitektura to opis obwodów elektrycznych komputera, jednostki centralnej lub cyfrowego procesora sygnałowego, który wystarcza do pełnego opisu działania sprzętu.
P: Jak uczeni odnoszą się do tego pojęcia?
O: Uczeni używają terminu "organizacja komputera" w odniesieniu do mikroarchitektury.
P: Jak ludzie z branży komputerowej odnoszą się do tego pojęcia?
O: Ludzie z branży komputerowej częściej mówią "mikroarchitektura", gdy odnoszą się do tego pojęcia.
P: Jakie dwie dziedziny składają się na architekturę komputera?
O: Mikroarchitektura i architektura zbioru instrukcji (ISA) stanowią razem dziedzinę architektury komputera.
P: Co oznacza skrót ISA?
O: ISA to skrót od Instruction Set Architecture.
P: Co oznacza skrót µarch? A: µArch to skrót od Microarchitecture.
Powiązane artykuły
Autor
AlegsaOnline.com Mikroarchitektura procesora — definicja, elementy i zasady działania Leandro Alegsa
URL: https://pl.alegsaonline.com/art/64586
Źródła
- computer.org : IEEE Computer Society
- extremetech.com : PC Processor Microarchitecture