Korelacja w statystyce — definicja, rodzaje i interpretacja wyników
Poznaj definicję, rodzaje korelacji i sposób interpretacji wyników — praktyczne przykłady i wskazówki, kiedy korelacja ≠ przyczynowość.
W statystyce i teorii prawdopodobieństwa, korelacja opisuje stopień i kierunek zależności między dwoma zestawami danych lub zmiennych. Innymi słowy, mówi nam, jak bardzo wartości jednej zmiennej są powiązane z wartościami drugiej. Korelacja może dotyczyć związków liniowych lub nieliniowych i występuje zarówno w analizach eksploracyjnych, jak i w modelowaniu.
Galeria obrazów
3 Obrazy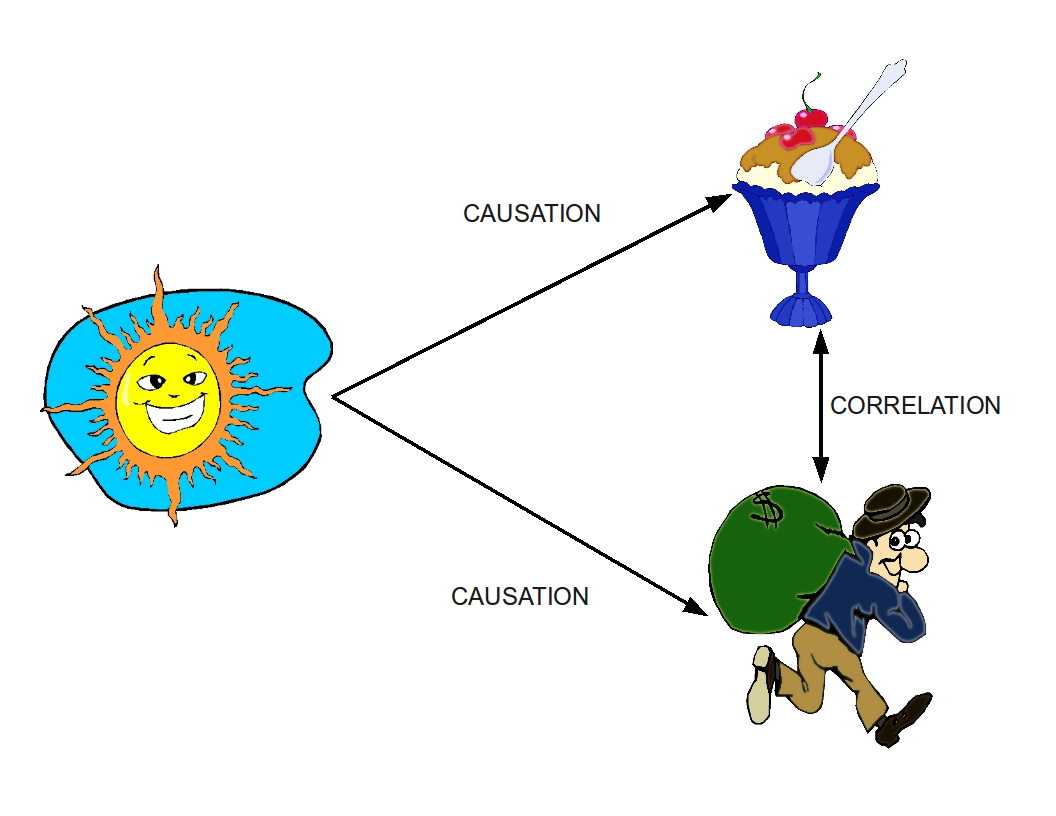

Rodzaje korelacji
- Korelacja dodatnia: gdy wartości obu zmiennych rosną razem — wzrost jednej zmiennej towarzyszy wzrostowi drugiej.
- Korelacja ujemna: gdy wzrost jednej zmiennej wiąże się ze spadkiem drugiej.
- Brak korelacji (korelacja zerowa): brak wyraźnego związku liniowego między zmiennymi — nie oznacza to jednak braku jakiejkolwiek zależności (może istnieć silna zależność nieliniowa).
Najczęściej stosowane miary korelacji
- Współczynnik korelacji Pearsona (r): mierzy siłę i kierunek zależności liniowej. Przyjmuje wartości od −1 do 1, gdzie 1 oznacza idealną korelację dodatnią, −1 idealną korelację ujemną, a 0 brak korelacji liniowej. Matematycznie r = cov(X,Y) / (σX σY), gdzie cov to kowariancja, a σX, σY odchylenia standardowe.
- Korelacja rang Spearmana (ρ): opiera się na rangach danych i mierzy monotoniczne (niekoniecznie liniowe) zależności. Jest mniej czuła na odstające wartości i rozkład danych niż Pearson.
- Korelacja Kendalla (τ): również działa na rangach i ocenia zgodność uporządkowań par obserwacji — często używana przy mniejszych próbach lub gdy dane mają wiele związań rangowych.
- Partialna korelacja: mierzy związek pomiędzy dwiema zmiennymi po kontrolowaniu wpływu jednej lub kilku zmiennych trzecich.
Interpretacja wyników
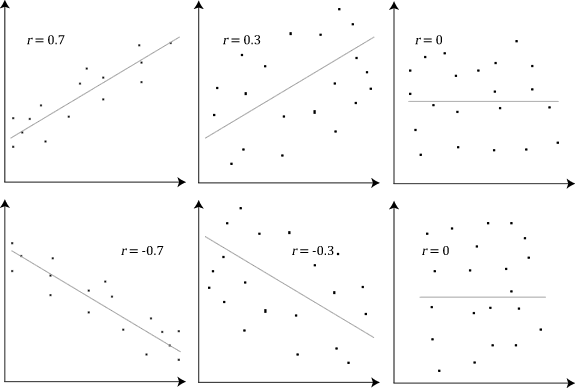
- Współczynnik korelacji interpretuje się zwykle jako miarę siły związku liniowego: im wartość bezwzględna bliższa 1, tym silniejszy związek liniowy. Przykładowe, często stosowane (orientacyjne) progi:
- 0–0.1: bardzo słaba lub brak korelacji
- 0.1–0.3: słaba korelacja
- 0.3–0.5: umiarkowana korelacja
- 0.5–0.7: silna korelacja
- 0.7–0.9: bardzo silna korelacja
- 0.9–1.0: niemal doskonała korelacja
- R^2 (współczynnik determinacji): w przypadku regresji liniowej R^2 = r^2 (dla jednej zmiennej objaśniającej) i informuje, jaka część zmienności zmiennej zależnej jest wyjaśniana przez zmienność zmiennej niezależnej.
- Wielkość próby ma znaczenie: przy bardzo dużych próbach nawet niewielkie wartości r mogą być statystycznie istotne, ale praktycznie nieistotne.
Testowanie istotności i przedziały ufności
- Istnieją testy statystyczne (np. test t dla współczynnika Pearsona) sprawdzające hipotezę zerową H0: r = 0. Wynik testu (p-value) informuje o istotności statystycznej korelacji.
- Zaleca się raportowanie nie tylko p-value, ale też wartości współczynnika, przedziału ufności dla współczynnika oraz rozmiaru próby.
Pułapki i ograniczenia
- Korelacja nie oznacza związku przyczynowego. Dwa zjawiska mogą korelować z powodu czynnika trzeciego (konfundera) lub przypadkowo. Przykład: sprzedaż lodów i liczba utonięć rosną razem latem — tu czynnikiem wspólnym jest temperatura.
- Wpływ odstających obserwacji (outliers): pojedyncze skrajne wartości mogą znacząco zmienić wartość współczynnika Pearsona.
- Brak wrażliwości na nieliniowość: Pearson mierzy zależność liniową — dla zależności nieliniowych jego wartość może być bliska zeru mimo silnego związku.
- Simpson’s paradox: uogólnienia na poziomie agregatów mogą prowadzić do sprzecznych wniosków w porównaniu z analizą podgrup.
Wizualizacja i praktyczne wskazówki
- Wykres rozrzutu (scatterplot): podstawowe narzędzie do oceny korelacji — często rysuje się na nim linię najlepszego dopasowania (regresji) lub krzywe dopasowania (np. LOESS) aby lepiej uwidocznić strukturę zależności.
- Macierz korelacji i heatmapy: przy wielu zmiennych warto użyć macierzy korelacji, która pokazuje pary współczynników oraz umożliwia szybką identyfikację silnych zależności.
- Kontrola zmiennych: rozważ użycie korelacji cząstkowych, regresji wielowymiarowej lub analiz przyczynowych, jeśli celem jest weryfikacja efektów po uwzględnieniu potencjalnych konfundujących czynników.
- Raportowanie wyników: podawaj metodę obliczenia (Pearson, Spearman, Kendall), wartość współczynnika, przedział ufności, p-value oraz liczbę obserwacji.
W praktyce dobór miary korelacji i interpretacja wyników zależą od rodzaju danych (ciągłe, porządkowe), rozkładu, obecności outlierów i celu analizy. Na wykresie rozrzutu ludzie często rysują linię najlepszego dopasowania, aby pokazać kierunek i charakter zależności, ale przed sformułowaniem wniosków warto rozważyć wszystkie powyższe ograniczenia i dodatkowe analizy.

Wyjaśnianie korelacji
Silna i słaba to słowa używane do opisania korelacji. Jeśli istnieje silna korelacja, wtedy wszystkie punkty są blisko siebie. Jeśli korelacja jest słaba, wtedy wszystkie punkty są od siebie oddalone. Istnieją sposoby, aby liczby pokazywały, jak silna jest korelacja. Pomiary te nazywane są współczynnikami korelacji. Najbardziej znanym jest współczynnik korelacji iloczynu i momentu Pearsona. Wprowadzasz dane do formuły, a ona daje ci liczbę. Jeśli liczba ta wynosi 1 lub -1, to mamy do czynienia z silną korelacją. Jeśli odpowiedź wynosi 0, wtedy nie ma korelacji. Innym rodzajem współczynnika korelacji jest współczynnik korelacji rang Spearmana.
Korelacja a związek przyczynowy
Korelacja nie zawsze oznacza, że jedna rzecz powoduje drugą (związek przyczynowy), ponieważ coś innego mogło spowodować obie rzeczy. Na przykład, w gorące dni ludzie kupują lody, a także chodzą na plażę, gdzie niektórzy są zjadani przez rekiny. Istnieje korelacja między sprzedażą lodów a atakami rekinów (w tym przypadku obie te rzeczy rosną wraz ze wzrostem temperatury). Ale to, że sprzedaż lodów wzrasta nie oznacza, że sprzedaż lodów powoduje (przyczynowo) więcej ataków rekinów lub odwrotnie.
Ponieważ korelacja nie implikuje związku przyczynowego, naukowcy, ekonomiści itp. będą testować swoje teorie poprzez tworzenie izolowanych środowisk, w których tylko jeden czynnik jest zmieniany (tam, gdzie jest to możliwe). Jednakże politycy, sprzedawcy, serwisy informacyjne i inni często sugerują, że dana korelacja implikuje przyczynowość. Może to wynikać z niewiedzy lub chęci przekonania. W ten sposób raport informacyjny może przyciągnąć uwagę mówiąc, że ludzie, którzy częściej spożywają dany produkt mają określony problem zdrowotny, sugerując związek przyczynowy, który w rzeczywistości może być spowodowany czymś innym.
Powiązane strony
- Cohen, J., Cohen P., West, S.G., & Aiken, L.S. (2003). Applied multiple regression/correlation analysis for the behavioral sciences. (3rd ed.) Hillsdale, NJ: Lawrence Erlbaum Associates.
Pytania i odpowiedzi
P: Co to jest korelacja?
O: Korelacja to sposób na wskazanie, jak blisko powiązane są dwa zestawy danych.
P: Czy korelacja oznacza, że jeden zestaw danych powoduje drugi?
O: Nie, korelacja nie zawsze oznacza, że jeden zestaw danych powoduje drugi. W rzeczywistości często występuje trzeci czynnik.
P: Jakie są dwa kierunki korelacji?
O: Dwa kierunki korelacji są dodatnie i ujemne.
P: Co oznacza dodatnia korelacja?
O: Dodatnia korelacja oznacza, że dwa zestawy danych rosną razem.
P: Co oznacza korelacja ujemna?
Ujemna korelacja oznacza, że jeden zestaw danych rośnie, a drugi spada.
P: Czy istnieją różne miary korelacji?
O: Tak, wiele różnych miar korelacji jest używanych w różnych sytuacjach.
P: W jaki sposób ludzie często pokazują kierunek korelacji na wykresie punktowym?
O: Ludzie często rysują linię najlepszego dopasowania, aby pokazać kierunek korelacji na wykresie rozrzutu.
Powiązane artykuły
Autor
AlegsaOnline.com Korelacja w statystyce — definicja, rodzaje i interpretacja wyników Leandro Alegsa
URL: https://pl.alegsaonline.com/art/23228