Relacyjny model bazy danych — definicja, zasady, SQL (Codd 1969)
Poznaj relacyjny model bazy danych (Codd 1969): definicja, zasady i mapowanie na SQL — praktyczny przewodnik dla programistów i administratorów.
Relacyjny model zarządzania bazą danych jest modelem bazy danych opartym na logice predykatów pierwszego rzędu. Edgar F. Codd zaproponował go w 1969 roku. W relacyjnym modelu bazy danych, wszystkie dane są reprezentowane w kategoriach krotek, pogrupowanych w relacje. Baza danych zorganizowana zgodnie z modelem relacyjnym nazywana jest relacyjną bazą danych.
Celem modelu relacyjnego jest zapewnienie deklaratywnej metody określania danych i zapytań: użytkownicy bezpośrednio określają, jakie informacje zawiera baza danych i jakie informacje chcą z niej uzyskać. Struktura, w której przechowywane są dane, oraz zadanie odpowiadania na żądania użytkowników i pobierania danych jest pozostawione systemowi bazy danych i nie jest widoczne dla użytkownika.
Większość relacyjnych baz danych używa języka definicji danych i zapytań SQL; systemy te implementują to, co można uznać za inżynierskie przybliżenie modelu relacyjnego. Tabela w schemacie bazy danych SQL odpowiada zmiennej predykatu; zawartość tabeli - relacji; ograniczenia klucza, inne ograniczenia i zapytania SQL odpowiadają predykatom. Obecnie wiele systemów baz danych różni się od oryginalnego modelu. Codd zaciekle argumentował przeciwko odstępstwom, które naruszają oryginalne zasady.
Galeria obrazów
1 Obraz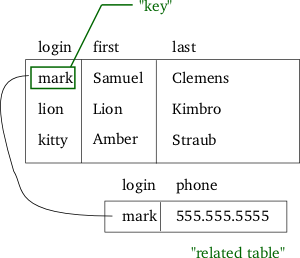
Podstawowe pojęcia
- Relacja — zbiór krotek (wierszy) o tej samej strukturze; w praktyce odpowiada tabeli.
- Krotka — pojedynczy rekord (wiersz) relacji, z wartościami przypisanymi do atrybutów.
- Atrybut — kolumna relacji określająca typ danych i nazwę pola.
- Domena — zbiór dopuszczalnych wartości dla atrybutu.
- Schemat relacji — nazwy atrybutów i ich domeny; schemat bazy danych to zbiór schematów relacji.
- Klucz — atrybut lub kombinacja atrybutów jednoznacznie identyfikująca krotkę (np. klucz podstawowy).
- Ograniczenia integralności — reguły zapewniające poprawność danych: integralność encji, integralność referencyjna, ograniczenia domeny itp.
Operacje i algebra relacyjna
Model relacyjny jest podstawą dla formalnych operacji na relacjach, znanych jako algebra relacyjna i rachunek relacyjny. Do najważniejszych operacji należą:
- selekcja (wybór wierszy),
- projekcja (wybór kolumn),
- złączenie (join),
- sumowanie (union), różnica (difference), część wspólna (intersection),
- przekształcenia i renamowanie atrybutów.
Algebra relacyjna daje formalny fundament do optymalizacji zapytań oraz dowodzenia poprawności transformacji zapytań wykonywanych przez systemy zarządzania bazą danych.
Zasady Codd'a i reguły integralności
Edgar F. Codd sformułował zbiór zasad opisujących oczekiwane właściwości systemów relacyjnych; później rozszerzył je do tzw. 12 reguł Codda (opublikowanych w 1985). Najważniejsze idee to:
- informacyjna reguła — wszystkie dane reprezentowane są jako wartości w relacjach (tablicach);
- gwarantowany dostęp — każda wartość jest dostępna przez określenie nazwy tabeli, nazwy kolumny i klucza;
- niejawne wartości NULL — system powinien traktować brak wartości w ustalony sposób (Codd postulował systemową obsługę NULL);
- niezależność danych — rozdział struktury logicznej i fizycznej (niezależność fizyczna i logiczna), co umożliwia zmiany implementacyjne bez naruszenia aplikacji;
- kompletny język danych — jednorodny, deklaratywny język (np. SQL) do definiowania, manipulowania i kontroli danych.
Reguły te były przedstawione jako punkt odniesienia — w praktyce wiele implementacji (szczególnie SQL) odstąpiło od niektórych założeń (np. obsługa NULL, występowanie duplikatów, porządek wyników), co było przedmiotem krytyki Codd'a.
SQL a model relacyjny
SQL jest najpowszechniejszym językiem używanym z relacyjnymi bazami danych. Implementuje większość koncepcji modelu relacyjnego, ale również wprowadza rozszerzenia i odstępstwa:
- tabele SQL odpowiadają relacjom, ale SQL dopuszcza powtarzające się wiersze (multizbiory) — klasyczny model relacyjny traktuje relację jako zbiór (bez duplikatów);
- SQL wprowadza wartość NULL reprezentującą nieznane lub brakujące dane — semantyka NULL jest nietrywialna i odbiega od pierwotnej formalizacji Codd'a;
- SQL definiuje bogaty język DDL (tworzenie struktur), DML (operacje na danych) i DCL (kontrola dostępu), co czyni go praktycznym, lecz nie czysto formalnym, odwzorowaniem modelu.
Normalizacja i zapobieganie anomaliom
Relacyjny model kładzie duży nacisk na poprawną strukturę danych. Normalizacja to proces rozbijania danych na relacje w taki sposób, aby zminimalizować redundancję i uniknąć anomalii przy wstawianiu, aktualizacji i usuwaniu danych. Podstawowe postacie normalne to:
- 1NF (pierwsza postać normalna) — atomowe wartości atrybutów,
- 2NF, 3NF — eliminacja częściowych i przechodnich zależności funkcyjnych,
- BCNF — silniejsza forma 3NF, wymagająca, by każdy determinant był kluczem kandydującym.
Zalety i ograniczenia
- Zalety:
- czytelna, deklaratywna reprezentacja danych,
- możliwość użycia formalnych narzędzi (algebra, rachunek) do optymalizacji i dowodzenia,
- silne mechanizmy integralności i transakcji w większości RDBMS,
- duże ekosystemy narzędzi i języka SQL.
- Ograniczenia:
- w przypadku bardzo złożonych, hierarchicznych lub grafowych danych model relacyjny może wymagać skomplikowanych złączeń i denormalizacji,
- odstępstwa SQL od formalnego modelu (NULL, multizbiory, kolejność) komplikują semantykę,
- skala i wydajność: duże rozproszone i nietrwałe obciążenia spowodowały rozwój alternatywnych modeli (NoSQL), które oferują inny kompromis między spójnością, dostępnością i wydajnością).
Podsumowanie
Relacyjny model baz danych, zaproponowany przez E. F. Codd'a w 1969 roku, pozostaje fundamentem współczesnych systemów zarządzania danymi. Jego formalne podstawy (logika predykatów, algebra relacyjna), zasady integralności i procesy normalizacji umożliwiają tworzenie spójnych, przewidywalnych i dobrze zorganizowanych baz danych. Jednocześnie praktyczne implementacje (zwłaszcza SQL) rozwijały model, dodając funkcje użyteczne w realnych systemach kosztem niektórych założeń teoretycznych.


Pytania i odpowiedzi
P: Czym jest relacyjny model zarządzania bazami danych?
O: Relacyjny model zarządzania bazą danych to model bazy danych oparty na logice predykatów pierwszego rzędu.
P: Kto i kiedy zaproponował relacyjny model zarządzania bazami danych?
O: Edgar F. Codd zaproponował relacyjny model zarządzania bazami danych w 1969 roku.
P: W jaki sposób dane są reprezentowane w relacyjnym modelu bazy danych?
O: W relacyjnym modelu bazy danych wszystkie dane są reprezentowane w postaci krotek pogrupowanych w relacje.
P: Jak nazywa się baza danych zorganizowana w modelu relacyjnym?
O: Baza danych zorganizowana zgodnie z modelem relacyjnym nazywana jest relacyjną bazą danych.
P: Jaki jest cel modelu relacyjnego?
O: Celem modelu relacyjnego jest zapewnienie deklaratywnej metody określania danych i zapytań.
P: Jakiego języka używa większość relacyjnych baz danych?
O: Większość relacyjnych baz danych korzysta z języka definicji danych i zapytań SQL.
P: W jaki sposób tabela, zawartość tabeli, ograniczenia klucza, inne ograniczenia i zapytania SQL odpowiadają predykatom w modelu relacyjnym?
O: W modelu relacyjnym tabela w schemacie bazy danych SQL odpowiada zmiennej predykatu; zawartość tabeli - relacji; ograniczenia kluczowe, inne ograniczenia i zapytania SQL odpowiadają predykatom.
Powiązane artykuły
Autor
AlegsaOnline.com Relacyjny model bazy danych — definicja, zasady, SQL (Codd 1969) Leandro Alegsa
URL: https://pl.alegsaonline.com/art/82000
Źródła
- acm.org : "A Relational Model of Data for Large Shared Data Banks"
- doi.org : 10.1145/362384.362685
- knowledge.fhwa.dot.gov : Data Integration Glossary